Hello,
i am experiencing serious issue with serversideup/php:beta-8.2-fpm-nginx-alpine combines with Google Cloud Run.
Dockerfile:
FROM serversideup/php:beta-8.2-fpm-nginx-alpine
ENV S6_CMD_WAIT_FOR_SERVICES=1
ENV AUTORUN_ENABLED false
ENV AUTORUN_LARAVEL_STORAGE_LINK true
ENV PHP_FPM_PM_CONTROL ondemand
ENV PHP_FPM_PM_MAX_CHILDREN 100
ENV PHP_MAX_EXECUTION_TIME 600
# Install Cloud SQL Proxy
RUN curl -o /usr/sbin/cloud-sql-proxy https://storage.googleapis.com/cloud-sql-connectors/cloud-sql-proxy/v2.7.1/cloud-sql-proxy.linux.amd64
RUN chmod +x /usr/sbin/cloud-sql-proxy
# Copy startup.sh in entrypoints directory
COPY --chmod=755 ./deployment/build/entrypoint.d/ /etc/entrypoint.d/
RUN pwd
RUN docker-php-serversideup-s6-init
# Copy website data
COPY backend/ /var/www/html
# Fix permissions
RUN chown -R nginx:nginx /var/www/html
Cloud run arguments:
--allow-unauthenticated
--min-instances=1
--max-instances=10
--cpu=1
--memory=2048Mi
--timeout=600
--concurrency=30
--cpu-throttling
--port=80
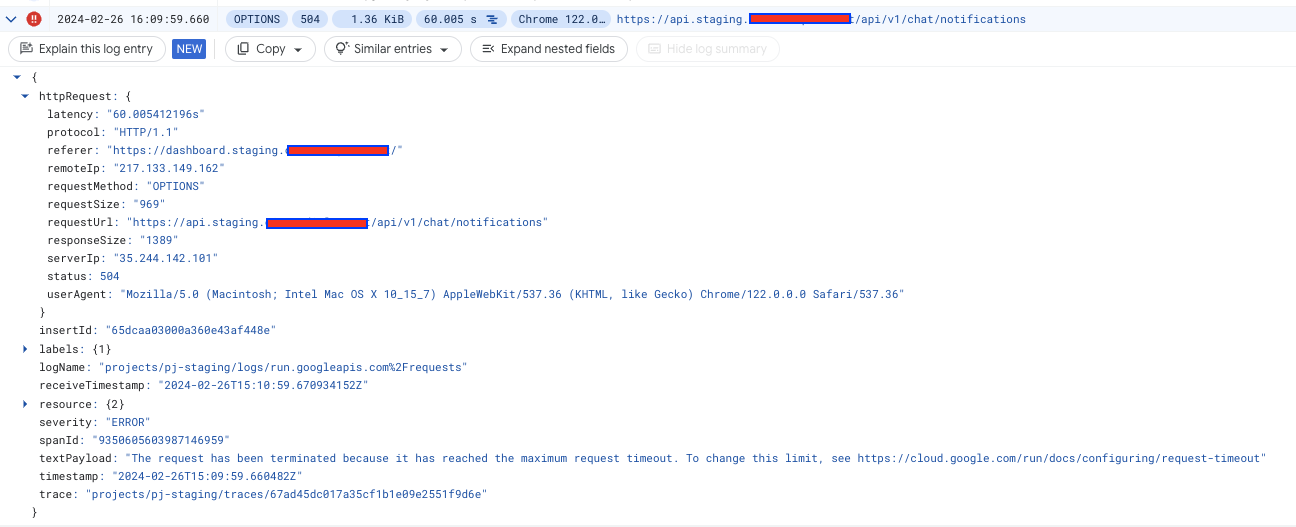
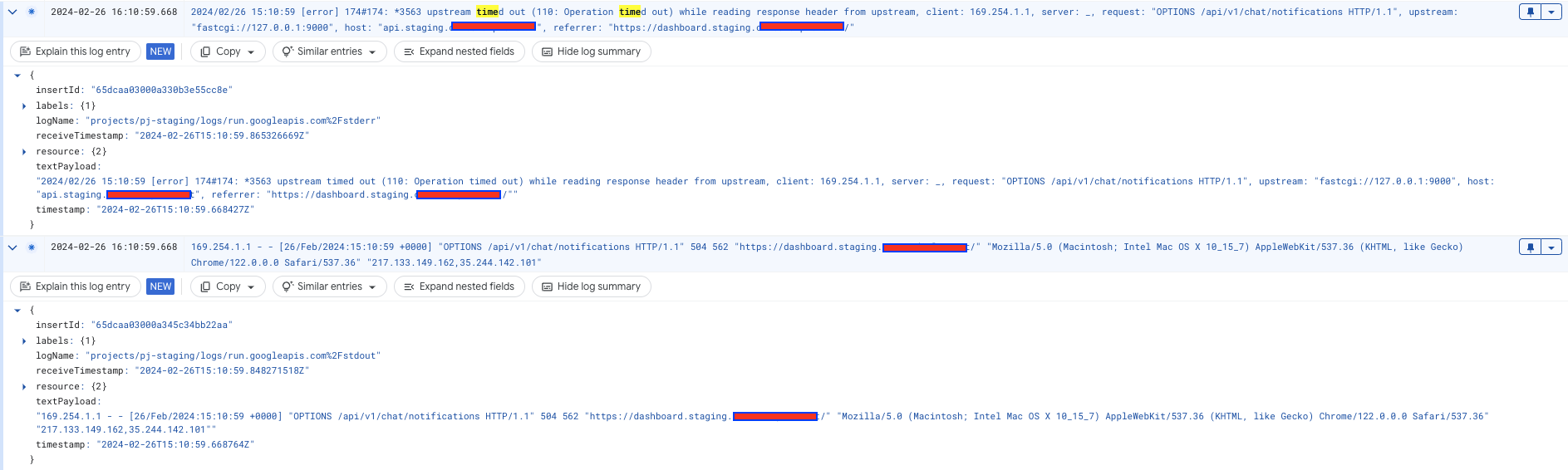
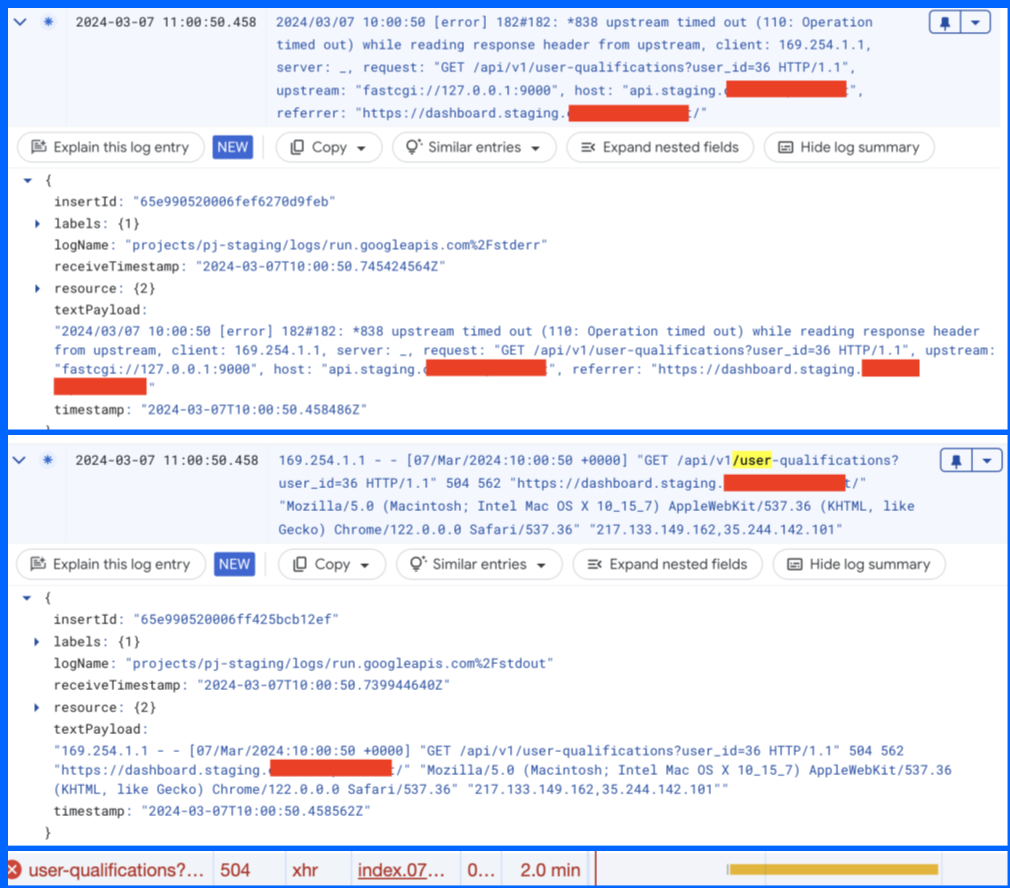
The errors are completely random, 200 requests can go fine and 1 fail. Also it’s not a specific endpoint or call type (OPTIONS or GET).
We are using also these two libraries GitHub - stackkit/laravel-google-cloud-scheduler and GitHub - stackkit/laravel-google-cloud-tasks-queue: Use Google Cloud Tasks as the queue driver for Laravel; both requests can fail sometimes.
I’ve been trying to figure out the source of the problem for weeks with no solution.
We are talking about Laravel 10, with all the patches.
The errors have no sense, OPTIONS and others requests take less that 1 second to be done.
(second image because i can only publish one per post)
This is indeed odd behavior. Replicating this will be very challenging.
Are you able to put the containers into DEBUG mode and get more logs what’s going on? It could possibly be something in the PHP application not responding back?
Thanks @jaydrogers, we are still monitoring the issue and today we have set the LOG_OUTPUT_LEVEL env variable to debug.
I will keep you updated
1 Like
@jaydrogers no news using log level debug.
I am going to create a copy 1:1 of the infrastructure deploying a vanilla Laravel installation in order to understand what the cause could be.
I will keep the thread updated, thanks
Great idea, thank you!
The less customizations/variables we have, the better chance we will be able to replicate and implement a fix.
Thanks for staying on top of this!
Thanks for the update! Keep me posted 
Issue related to the cloud tasks timeout found, nginx timeout is not configurable in serversideup images.
The fix was to provide custom site-opts.d folder and replace the provided ones:
listen 80 default_server;
listen [::]:80 default_server;
root $NGINX_WEBROOT;
# Set allowed "index" files
index index.html index.htm index.php;
server_name _;
charset utf-8;
# Set max upload to 2048M
client_max_body_size 2048M;
# Healthchecks: Set /ping to be the healhcheck URL
location /ping {
access_log off;
# set max 5 seconds for healthcheck
fastcgi_read_timeout 5s;
include fastcgi_params;
fastcgi_param SCRIPT_NAME /ping;
fastcgi_param SCRIPT_FILENAME /ping;
fastcgi_pass 127.0.0.1:9000;
}
# Have NGINX try searching for PHP files as well
location / {
try_files $uri $uri/ /index.php?$query_string;
}
# Pass "*.php" files to PHP-FPM
location ~ \.php$ {
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
proxy_connect_timeout 300s;
proxy_read_timeout 300s;
fastcgi_read_timeout 300s;
include fastcgi_params;
}
# additional config
include /etc/nginx/server-opts.d/*.conf;
# Copy nginx server-opts
COPY --chmod=755 ./deployment/build/site-opts.d/ /etc/nginx/site-opts.d/
Now i am gonna push the fix in staging to see if it is somehow correlated to others timeout.
As always, i will keep you updated 
@jaydrogers cloud tasks error is solved.
The issue regarding external http calls still here.
Nginx fastcgi timeout is set at 120s.
PHP FPM max_execution_time is set at 130s.
Cloud Run timeout is set at 140s.
Nginx is killing the request, the problem is: why?
It is a OPTION request, there is no logic reason for that. Do you have any idea?
http.conf.template
listen 80 default_server;
listen [::]:80 default_server;
root $NGINX_WEBROOT;
# Set allowed "index" files
index index.html index.htm index.php;
server_name _;
charset utf-8;
# Set max upload to 2048M
client_max_body_size 2048M;
# Healthchecks: Set /ping to be the healhcheck URL
location /ping {
access_log off;
# set max 5 seconds for healthcheck
fastcgi_read_timeout 5s;
include fastcgi_params;
fastcgi_param SCRIPT_NAME /ping;
fastcgi_param SCRIPT_FILENAME /ping;
fastcgi_pass 127.0.0.1:9000;
}
# Have NGINX try searching for PHP files as well
location / {
try_files $uri $uri/ /index.php?$query_string;
}
# Pass "*.php" files to PHP-FPM
location ~ \.php$ {
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
proxy_connect_timeout 120s;
proxy_read_timeout 120s;
fastcgi_read_timeout 120s;
include fastcgi_params;
proxy_no_cache 1;
proxy_cache_bypass 1;
}
# additional config
include /etc/nginx/server-opts.d/*.conf;
I really appreciate you keeping this thread updated.
Are you 100% sure that NGINX is killing the request. Are you seeing it in the debug log?
The other layers below that would be S6 Overlay, then Docker itself.
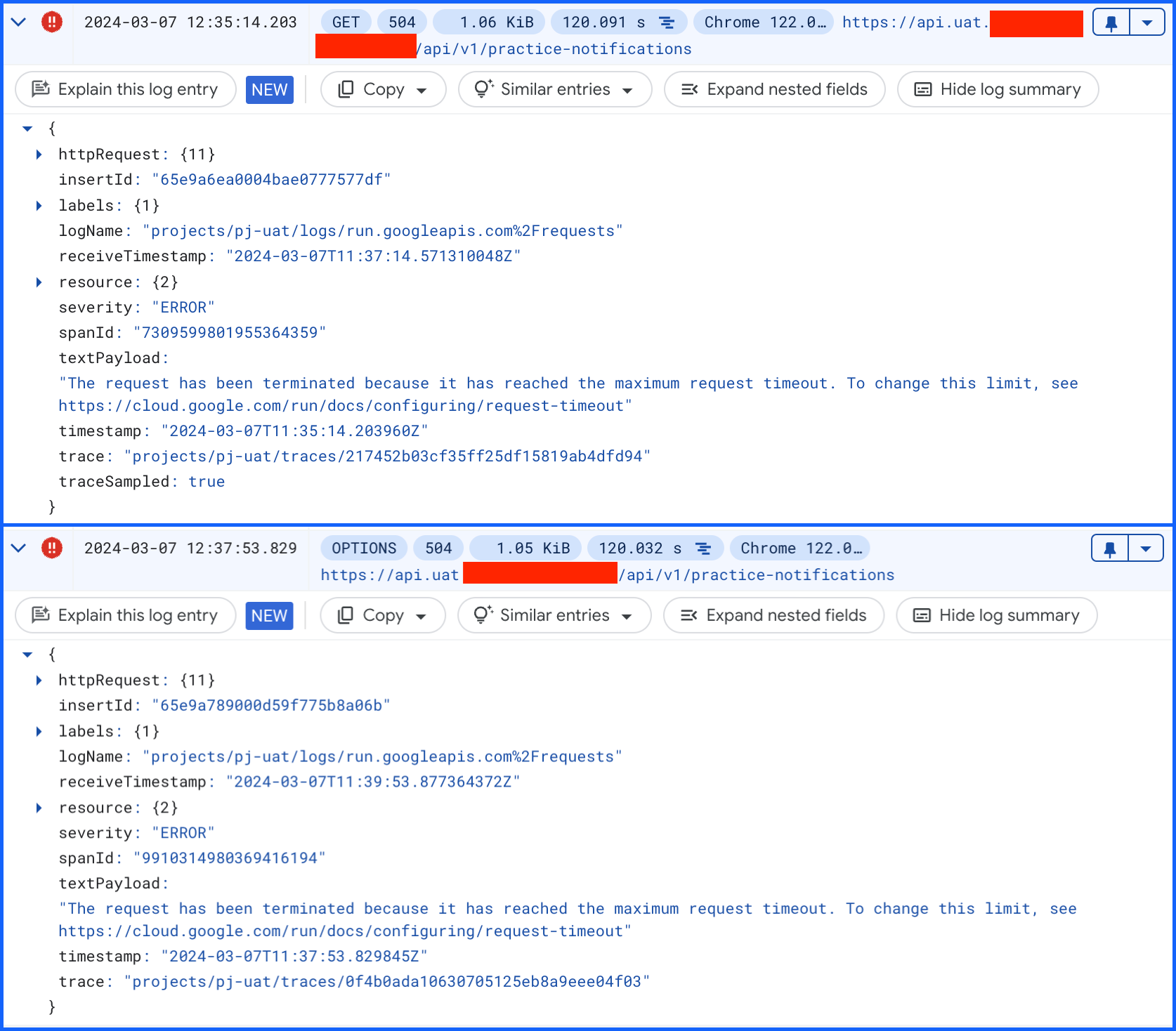
I can’t upload more than 1 image but yes, the timeout is exactly 120 seconds (the one set in Nginx)
I’ve tried disabling keep_alive but didn’t fix the issue.
Hope you can help us 
Tried using apache version…no luck. The webserver is still “losing” the request and throwing the timeout after 120 seconds.
At this point i have no clue of what the root cause can be.
FROM serversideup/php:beta-8.2-fpm-apache
ENV S6_CMD_WAIT_FOR_SERVICES=1
ENV AUTORUN_ENABLED false
ENV AUTORUN_LARAVEL_STORAGE_LINK true
ENV PHP_FPM_PM_CONTROL static
ENV PHP_FPM_PM_MAX_CHILDREN 20
ENV PHP_MAX_EXECUTION_TIME 130
ENV LOG_OUTPUT_LEVEL debug
RUN apt update \
&& apt install -y \
freetype* \
libfreetype6-dev \
libpng-dev \
libjpeg-dev
RUN docker-php-ext-configure gd --with-freetype --with-jpeg
RUN docker-php-ext-install bcmath gd
# Copy apache vhost-templates
COPY --chmod=755 ./deployment/build/vhost-templates/ /etc/apache2/vhost-templates/
# Install Cloud SQL Proxy
RUN curl -o /usr/sbin/cloud-sql-proxy https://storage.googleapis.com/cloud-sql-connectors/cloud-sql-proxy/v2.7.1/cloud-sql-proxy.linux.amd64
RUN chmod +x /usr/sbin/cloud-sql-proxy
# Copy startup.sh in entrypoints directory
COPY --chmod=755 ./deployment/build/entrypoint.d/ /etc/entrypoint.d/
RUN docker-php-serversideup-s6-init
# Copy website data
COPY backend/ /var/www/html
# Fix permissions
RUN chown -R www-data:www-data /var/www/html
Is there a way that we can break this down into the simplest reproducible steps possible?
I want to see if this does this locally. The error that you’re posting is a Google error, but I understand that error could be “downstream” from other timeouts.
If we can get an NGINX or PHP log saying it’s killing a long running process, then we can guarantee it’s something in the container.
I just want to see if this can be reproduced outside of Google’s infrastructure (since that could be a layer of complexity there too)
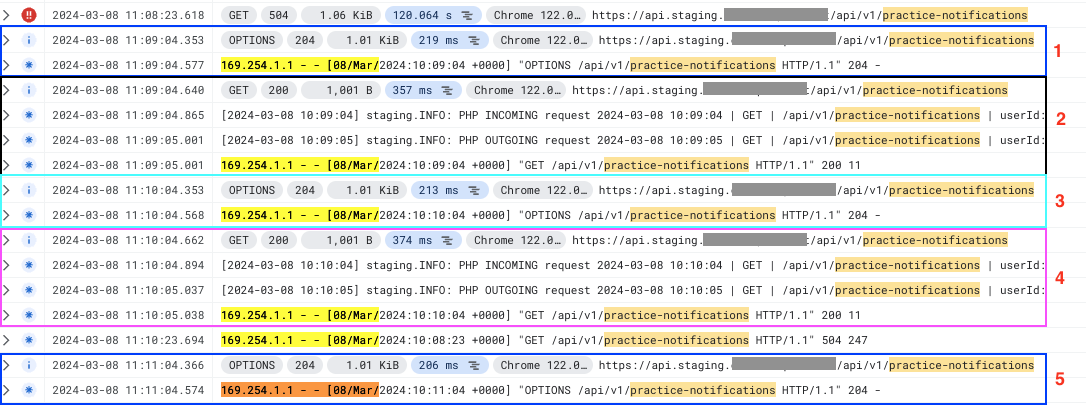
I can confirm that the request is entering the container, and then the web server kills it with timeout.
We added a custom Laravel middleware that logs any incoming/outgoing request (not OPTIONS one because they are handled by another middlware):
<?php
namespace App\Http\Middleware;
use Closure;
use Carbon\Carbon;
use Illuminate\Http\Request;
use Illuminate\Support\Facades\Log;
class LoggerMiddleware
{
/**
* Handle an incoming request.
*
* @param Request $request
* @param Closure $next
*
* @return mixed
*/
public function handle(Request $request, Closure $next)
{
if (config('app.env') === 'testing') {
return $next($request);
}
$user_id = $request->user()?->id;
$dt = new Carbon();
Log::info("PHP INCOMING request {$dt->toDateTimeString()} | {$request->getMethod()} | {$request->getPathInfo()} | userId: {$user_id}");
$response = $next($request);
$dt = new Carbon();
Log::info("PHP OUTGOING request {$dt->toDateTimeString()} | {$request->getMethod()} | {$request->getPathInfo()} | userId: {$user_id}");
// return the response
return $response;
}
}
Example one: the GET request joins the container and after exactly 120 seconds apache sends a 504.
Example two: the OPTIONS request joins the container and after exactly 120 seconds apache sends a 504. Here i’ve set the LOG_OUTPUT_LEVEL to debug
Is there anyway you can give me steps to replicate this locally on my machine?
Sorry for the late response, we wanted to be 100% sure before placing blame.
We were able to reproduce in a Laravel vanilla and it seems to be traceable to redis connection.
When Redis is disabled as connector, no issue is created.
Obviously we checked the Redis resource usage and there is nothing strange about it.
It’s absurd, could it be that Laravel isn’t made to scale horizontally and therefore doesn’t manage resource locking on Redis? Could it be that some sort of deadlock occurs?
What we notice is that the request enters the webserver (Apache or Nginx, it doesn’t matter), then passed to PHP FPM, but does not actually enter the application.
I think that something in the Laravel framework tries to interact with a key inside Redis (cache or even session) and in some specific cases, everything breaks.
No exception is thrown, even PHP FPM (120 second timeout) does not kill the operation; but instead it is the webserver that kills it (140 second timeout).
What do you think? What is your opinion on this?
Thanks in advance.
1 Like
Sorry I fell off the radar… My wife and I had our first child last month. Life got a little crazy to say the least hahaha.
The hangup in PHP-FPM because of Redis makes sense. If it’s relying on a job, I would be shocked if PHP-FPM was smart enough to understand the status of Redis. I’m sure it turns into a huge traffic jam of some sort.
Were you able to progress on this further while I was gone?
1 Like
Hello there,
I am new here, can you explain what are this discussion is all about?
So I can make some contribution too.